Stable Diffusion和基础模型初识
Models ,也称为 checkpoint files ,是预训练的稳定扩散权重,用于生成一般或特定类型的图像。
模型可以生成什么图像取决于用于训练它们的数据。如果训练数据中从来没有猫,模型将无法生成猫的图像。同样,如果你只用猫图像训练模型,它只会生成猫。
我们将介绍什么是模型,一些常见的模型(v1.4,v1.5,F222,Anything V3,[Open Journey v4](#open-journey-11),以及如何安装,使用和合并它们。
微调模型
什么是微调?
微调 是机器学习中的常用技术。它采用在宽数据集上训练的模型,并在窄数据集上训练更多。
经过微调的模型将偏向于生成与您的数据集相似的图像,同时保持原始模型的多功能性。
为什么要制造它们?
稳定的扩散很好,但并不是什么都擅长。例如,它可以并且将在提示中生成带有关键字“anime”的动漫风格图像。但是生成动漫子流派的图像可能很困难。您可以使用该子类型的图像微调模型,而不是修改提示。
它们是如何制成的?
两种主要的微调方法是 (1) Additional training 和 (2) Dreambooth。它们都从基本模型开始,例如 Stable Diffusion v1.4或v1.5。
Additional training 是通过使用您感兴趣的额外数据集训练基础模型来实现的。例如,您可以使用额外的老爷车数据集训练 Stable Diffusion v1.5,以使汽车的美感偏向子类型。
Dreambooth最初由谷歌开发,是一种将自定义主题注入文本到图像模型的 技术它适用于少至 3-5 个自定义图像。您可以拍几张自己的照片,然后使用 Dreambooth 将自己放入模型中。使用 Dreambooth 训练的模型需要一个特殊的关键字来调节模型。
还有另一种不太流行的微调技术称为文本反转(有时称为嵌入)。目标类似于 Dreambooth:将自定义主题注入到模型中,仅包含几个示例。专门为新对象创建一个新关键字。只有文本嵌入网络被微调,同时保持模型的其余部分不变。通俗地说,这就像用现有的词来描述一个新概念。
Models
有两组模型:v1 和 v2,本节只介绍 v1 模型。
有数以千计的微调稳定扩散模型。这个数字每天都在增加。以下是可用于一般用途的模型列表。
Stable diffusion v1.4

由 Stability AI 于 2022 年 8 月发布的 v1.4 模型被认为是第一个公开可用的稳定扩散模型。
您可以将 v1.4 视为通用模型。大多数时候,除非您对某些样式真的很挑剔,否则按原样使用就足够了。
Stable diffusion v1.5

v1.5 于 2022 年 10 月由 Stability AI 的合作伙伴 Runway ML 发布。该模型基于 v1.2 并经过进一步训练。
模型页面没有提到改进是什么。与 v1.4 相比,它产生的结果略有不同,但尚不清楚它们是否更好。
与 v1.4 一样,您可以将 v1.5 视为通用模型。
F222

F222 最初是为生成裸体而训练的,但人们发现它有助于生成具有正确身体部位关系的美丽女性肖像。有趣的是,与您的想法相反,它非常擅长制作美观的服装。
F222 适合人像。它很容易产生裸体。在提示中包括诸如“dress” 和“jeans”之类的衣柜术语。
Anything V3

Anything V3 是一种特殊用途的模型,经过训练可以生成高质量的动漫风格图像。您可以在文本提示中使用danbooru tag(如 1girl、white hair)。
它对于将名人塑造成胺风格很有用,然后可以将其与说明性元素无缝融合。
一个缺点是它产生的女性体型不成比例。我喜欢用 F222 调低它。
Open Journey

Open Journey 是使用Mid Journey v4生成的图像进行微调的模型。它具有不同的美感,是一个很好的通用模型。
触发关键字: mdjrny-v4 style
模型对比
以下是使用相同种子和步骤生成的图像

其他 models
有数百种稳定扩散模型可用。其中许多是专为生成特定风格而设计的专用模型。一些值得注意的是:
DreamShaper

Dreamshaper模型针对介于真实感和计算机图形之间的肖像插图风格 进行了微调。它易于使用,如果您喜欢这种风格,您会喜欢的。
ChilloutMix

ChilloutMix 是一种用于生成照片质量的亚洲女性的特殊模型。它就像 F222 的亚洲版本。与韩语 embedding ulzzang-6500-v1 一起使用以生成像 k-pop 这样的女孩。
像 F222 一样,它有时会生成裸体。抑制提示中的“dress” and “jeans””等衣柜术语,以及否定prompt中的“nude”。
Waifu-diffusion

Waifu Diffusion 是一种日本动漫风格。
Robo Diffusion

Robot Diffusion 是一个有趣的机器人风格模型,它将把你的每个对象变成一个机器人!
Mo-di-diffusion

Mo-di-diffusion是现代迪士尼风格。
如果您想生成一些类似 Pixar 的风格,则此模型适合您。
使用关键词: modern disney style
Inkpunk Diffusion

Inkpunk Diffusion 是 Dreambooth 训练的模型,具有非常鲜明的插图风格。
使用关键词:nvinkpunk
查找更多模型
您可以在Huggingface中找到更多模型。
Civitai是搜索模型的另一个重要资源。
v2 模型
Stability AI 发布了新的系列模型版本 2。目前发布了2.0和2.1;v2模型的主要变化是
- 除了 512×512 像素外,还提供更高分辨率的 768×768 像素版本。
- 您不能再生成露骨内容,因为色情材料已从培训中删除。
您可能会假设每个人都已经开始使用 v2 模型。然而,Stable Diffusion 社区发现图像在2.0。人们也难以使用名人姓名和艺术家姓名等具有影响力的关键词。
v2.1模型已经部分解决了这些问题。开箱即用的图像看起来更好。更容易产生艺术风格。
截至目前,大多数人还没有完全转向 2.1 模型。许多人偶尔使用它们,但大部分时间都花在 v1 模型上。
如何安装和使用模型
要在 AUTOMATIC1111 GUI 中安装模型,请下载检查点 (.ckpt) 文件并将其放在以下文件夹中
stable-diffusion-webui/models/Stable-diffusion/
按检查点下拉框旁边的重新加载按钮
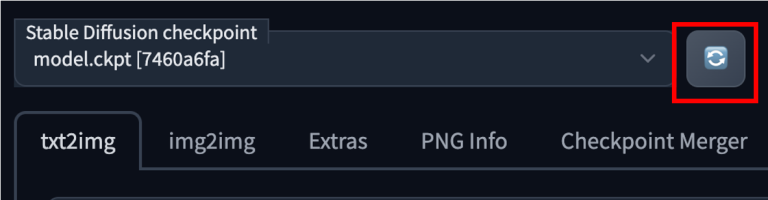
您应该会看到刚刚放入的检查点文件可供选择。选择新的检查点文件以使用该模型。
或者,您可以按“生成 ”下的“iPod”按钮。
将出现模型面板。选择检查点 选项卡并选择一个模型。
合并两个模型
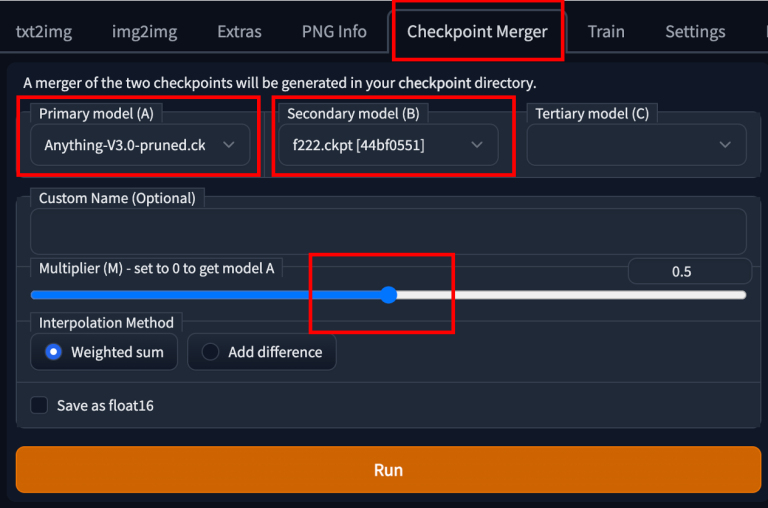
要使用 AUTOMATIC1111 GUI 合并两个模型,请转到Checkpoint Merger选项卡并在 Primary model (A) 和Secondary model (B) 中选择要合并的两个模型。
调整乘数(M)来调整两个模型的相对权重。将其设置为 0.5 将合并具有同等重要性的两个模型。
按Run 后,新合并的模型就可以使用了。
合并模型的示例
以下是合并F222和具有相同权重 (0.5)的Anything V3的示例图像;比较 F222、Anything V3 和 Merged(各占 50%):
合并后的模型介于逼真的 F222 和动漫 Anything V3 风格之间。这是一个非常好的用人物生成插图艺术的模型。
其他模型类型
四种主要类型的文件可以称为“Models”。让我们澄清一下,这样您就知道人们在谈论什么。
- Checkpoint models :这些是真正的稳定扩散模型。它们包含生成图像所需的一切。不需要额外的文件。它们很大,通常为 2 – 7 GB。他们是本文的主题。
- Textual inversions :也称为嵌入(embedding)。它们是定义新关键字以生成新对象或样式的小文件。它们很小,通常为 10 – 100 KB。您必须将它们与检查点模型一起使用。
- LoRA 模型 :它们是用于修改样式的检查点模型的小补丁文件。它们通常为 10-200 MB。您必须将它们与检查点模型一起使用。
- Hypernetworks :它们是添加到检查点模型的附加网络模块。它们通常为 5 – 300 MB。您必须将它们与检查点模型一起使用。