文生图
就是通过文字说明生成图片,文字可以是关键词的堆积或者一句完整的描述,关键词也被称为提示词、tag或者prompt,也有人称为咒语,后文都称tag。
以下实验在没有特殊说明时均采用的是chikmix_V2.safetensors模型,
参数如下:
masterpiece, best quality, (dark photo:1.3), photorealistic, 1girl, flat bangs, stunning innocent symmetry face, shirt, emotional, ulzzang, (PureErosFace_V1:0.7), full body
Negative prompt: (bad-artist:0.7), (worst quality, bad quality:1.3),
Steps: 30, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 3086903786, Size: 512x768, Model hash: 0bcee2e498, Model: chikmix_V2, Denoising strength: 0.35, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires upscaler: ESRGAN_4x
注意:在测试过程中会进行参数微调,但原始参数就是这个
模型下载
模型有多种下载渠道,像GitHub、C站、huggingface等;
不理解的可以看下教程2,在上篇文章中我们已经学会使用别人的tag生成我们自己的图片;
文生图参数说明
在上篇文章中我们采用了C站的一个图片tag,如下:
masterpiece, best quality, (dark photo:1.3), photorealistic, 1girl, flat bangs, stunning innocent symmetry face, shirt, emotional, ulzzang, (PureErosFace_V1:0.7)
Negative prompt: (bad-artist:0.7), (worst quality, bad quality:1.3),
ENSD: 31337, Size: 512x768, Seed: 3086903786, Model: ChikMix_v2, Steps: 30, Sampler: DPM++ SDE Karras, CFG scale: 7, Clip skip: 2, Model hash: 0bcee2e498, Hires upscale: 2, Hires upscaler: ESRGAN_4x, Denoising strength: 0.35
可以看到有很多参数,这些参数包括:tag、反向tag以及一些其他信息,如下:
ENSD: 31337, Size: 512x768, Seed: 3086903786, Model: ChikMix_v2, Steps: 30, Sampler: DPM++ SDE Karras, CFG scale: 7, Clip skip: 2, Model hash: 0bcee2e498, Hires upscale: 2, Hires upscaler: ESRGAN_4x, Denoising strength: 0.35
分别是:
-
ENSD: 31337:覆盖设置参数 - `Size: 512x768:分辨率
- `Seed: 3086903786:种子
-
Model: ChikMix_v2: 模型 -
Steps: 30: 采样迭代步数 -
Sampler: DPM++ SDE Karras: 采样方法 -
CFG scale: 7: tag相关性 -
Clip skip: 2: 覆盖设置参数 -
Model hash: 0bcee2e498: 模型hash -
Hires upscale: 2: 放大倍率 -
Hires upscaler: ESRGAN_4x: 放大算法 -
Denoising strength: 0.35: 重绘幅度
采样方法
Stable Diffusion提供了多种采样方法以适配众多特定的应用场景。没有绝对完美的采样方法,只有合适的。大家可以多进行尝试
- Euler a :富有创造力,不同步数可以生产出不同的图片, 超过30~40步效果不明显
- Euler:最最常见基础的算法,最简单的,也是最快的
- DDIM:收敛快,一般20步就差不多了
- LMS:eular的延伸算法,相对更稳定一点,30步就比较稳定了
- PLMS:再改进一点LMS
- DPM2:DDIM的一种改进版,它的速度大约是 DDIM 的两倍

以上是相同参数下只改变取样方法生成的图片对比
采样迭代步数
AI绘画的原理就是先随机生成一张噪声图片,然后一步一步向正负tag语义靠拢,迭代步数就是告诉AI,这样的步骤需要多少次,步骤越多,每一步移动越小也越精确。同时也成比例增加生成图像所需要的时间,大部分采样器超过50步后意义就不大了,一般设置为20,如果效果不佳再往上调。
一般在描述显卡性能时会说一秒多少步(it/s),或者倒数,多少秒一步(s/it),前者是越大约好,后者越小越好,下图是用我们上面的参数,步数分别设置1,2,3,5,10,15,20,30,50,80后的对比,采样方法使用的是DPM++ SDE Karras

面部修复
使用模型,对生成图片的人物面部(主要是三次元真人、二次元也有一定质量提高)进行修复,让人脸更像真人的人脸,具体设定在【设置】- 【面部修复】

- CodeFormer 和 GFPGAN ,至于那个更好,这个不好说,这个和模型相关,基本没改过,后文没有特殊说明,都使用CodeFormer
- CodeFormer权重参数:为0时效果最大,为1时效果最小,建议从0.5开始,左右尝试,找到自己喜欢的设置。
可平铺
主要用来生成贴图,一般不勾选,勾选后生成的图可能是这样的

高清修复
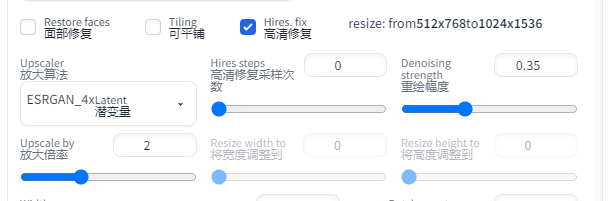
文生图在高分辨率下(1024 x 1024)会生成非常怪异的图像。而此插件这使得AI先在较低的分辨率下部分渲染你的图片,再通过算法提高图片到高分辨率,然后在高分辨率下再添加细节。
- 放大算法:如果不知道选什么,一般无脑选ESRGAN_4x、
- 高清修复采样次数:类比采样迭代步数理解,0表示沿用原来的步数
- 重绘幅度:放大后修改细节的程度,从0到1,数值越大,AI创意就越多,也就越偏离原图。
- 放大倍率:放大倍数,在原有宽度和长度上放大几倍,注意这个拉高需要更高的显存
如果原图是512 x 768,开了高分修复后则会变成1024 x1536,可以看到上方有类似提示
resize: from 512x768to1024x1536
一般建议先生成小图,在小图中找到合适的图后在开高分修复生成大图,提高速度,开高分修复会明显感受到造图速度变慢,下图为造图信息对比
- 不开高分:
Time taken: 12.89sTorch active/reserved: 2909/3668 MiB, Sys VRAM: 5806/12288 MiB (47.25%) - 两倍高分:
Time taken: 1m 42.26sTorch active/reserved: 5385/8818 MiB, Sys VRAM: 10956/12288 MiB (89.16%) - 三倍高分:二倍显存占用率已经达到89%,直接爆显存:OutOfMemoryError: CUDA out of memory
开启后细节部分处理的更好

生成批次
同样的配置,运行多少次,即批次
每批数量
一个批次中,生成几张图片,增大该值会增大显存使用,如果显存不足和增加批次即可,生成的总的数量=生成批次*每批数量,最终生成的图其实差别不大,所以直接使用批次就行。
宽度和高度
单位是像素,适当增加尺寸,AI会试图填充更多的细节进来,非常小的尺寸(低于256X256),会让AI没地方发挥,会导致图像质量下降,非常高的尺寸(大于1024X1024),会让AI乱发挥,会导致图像质量下降,增加尺寸需要更大的显存。
如果你想生成高分辨率图像,请使用高分修复放大尺寸的方法。
相同参数 改变分辨率效果如下:
-
128*128

-
512*512
-
1280*1280
-
1680*1680直接崩坏



提示词相关性
图像与tag的匹配程度,增加这个值将导致图像更接近你的提示,但过高会让图像色彩过于饱和,太高后在一定程度上降低了图像质量。可以适当增加采样步骤来抵消画质的劣化,一般在5~15之间为好,7,9,12是3个常见的设置值。
下图为提示词相关性分别为1,2,3,5,7,9,12,15,20,30的对比图,采样步数均为30步

发现面部有点崩坏,我们开启下面部修复看下效果:

随机种子
这个没搞懂,只是知道和AI绘画的原理有关;
设置方式如下:
- 种子为-1表示随机,即每次生成的图可能会不一样,批量生成图的时候种子不一样所以生成的图差别比较大
- 如果找到一个比较不错的种子,可点击绿色环回三角还原最后一次出图的种子,然后点击Extra对在该种子下生成的图继续进行微调,其中主要的参数是差异强度,值在0~1之间,如果想要基于原图产生更多的变化则向1靠拢。
- 差异随机种子,在随机种子的基础之上在进行随机,下图分别是Var strength 0.0,0.1,0.2,0.3;Var seed 为100,200,300时的生成效果:

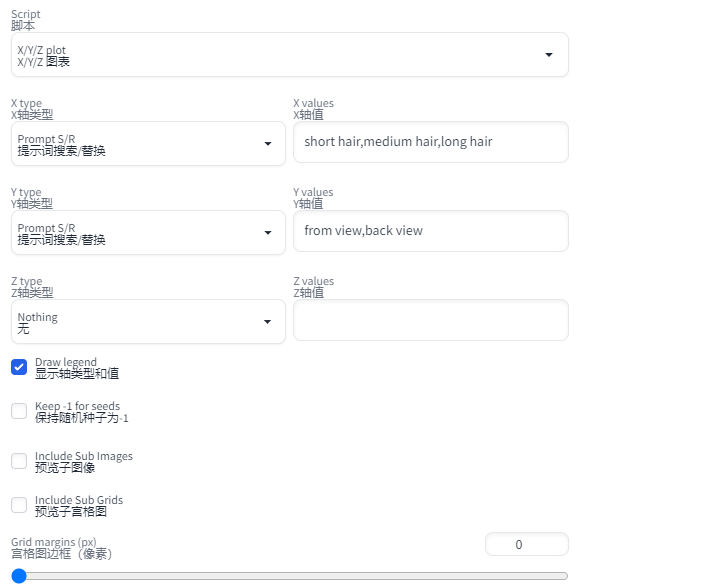
脚本
脚本功能很强大,一维对比图,二维矩阵图,三维矩阵图都可以通过脚本实现的;
提示词矩阵
- tag用|隔开
- 随机种子设置为
-1(DPM++ SDE Karras需要设置) - 需要替换的词放到正负tag的末尾
- 每个词前面都需要带一个
|
在正向tag末尾添加|white shirt|school uniform 则生成以下矩阵:

从文本框或文件载入提示词
从文本框或文件载入提示词,如下:
red hair
blue hair
green hair
出来的结果就是三张图,注意它会替覆盖掉正向tag,如下图:
X/Y/Z图表
X/Y/Z图表功能强大,可以对比多个条件下不同参数结果的差别,可以生成一维、二、三维对比结果
上面提到的差异强度和差异随机种子二维对比设置如下所示:

X/Y/Z每个参数都可以从下拉框中获取不同类型的值继续替换,其中比较常用的如提示词搜索/替换(Prompt S/R),大家可以多尝试不同的组合。